Abstract
We describe a system that enables the use of rhythmic input
for exploring Indian tabla drumming.
Rhythms drummed by the user on a pair of drum pads are
mapped to tabla phrases using a hidden Markov model
based recognizer. The recognized tabla phrases are played
back to the user, while an animated visual representation of
the phrase is displayed.
Keywords:
Multi-media, Tactile or gestural I/O,
Auditory I/O, Intelligent Systems, Educational applications,
Music applications.
Introduction
The term multimedia has come to be applied to
systems which make use of multiple
presentation media. However, the channel
through which users access the contents of these
presentations remains, in most contemporary systems,
strictly mono-media. Here, we focus on the subset of
multimedia systems which provide access to databases of
stored data, rather than to systems which enable
communications with other users. Interacting with these
systems, often called hypermedia systems,
typically involves selecting visual icons or keywords using
a pointing device. In this work, users learn about drumming
by doing drumming.
We propose an expansion of the notion of multimedia to
include multiple input media. Specifically, we have
developed a system for naive users to learn some basic
aesthetic ideas of tabla drumming as it is practiced in North
India. Our system responds to rhythmic "meta-tabla" input
drummed out by the user on two pressure-sensitive drum
pads. Meta-tabla is a partial specification of the tone and
rhythm of a phrase in tabla drumming. We use a hidden
Markov model (HMM) [5] of tabla phrases to build a
recognizer which maps the user's meta-tabla to a complete
phrase which might occur in tabla drumming. This work is
part of an ongoing project to provide multimedia access to
multimedia arts [4].
The use of multimedia input as a method for accessing
speech, text, and image data was discussed in [2]. In [6], a
spoken keyword was used as input to a wordspotting
system which located instances of the keyword in fluent
speech. Computer music systems typically provide access to
audio musical data by associating keywords or icons with
discrete aesthetic units of a musical stream such as melodic
motifs. In contrast to these systems, traditional and
electronic instruments map the physical gestures of skilled
users directly to musical expressions [3]. Our goal is to
provide novice users with access to musical content through
musical input.
TABLA DRUMMING
A tabla set consists of a pair of tuned drums with closed
bottoms. The tabla, played with the right
hand, and the larger baya, played with the left
hand, might be considered respectively as treble and bass
drums. A skilled tabla player can vary the pitch and timbre
of the drum strokes by varying the pressure, damping, and
shape of the hands on the drum. In the oral tradition of
tabla, musicians communicate compositions to each other
using onomatapaeic syllables, called bols, to
represent different drum strokes. For example, ta, te,
ti, and tun are played on the tabla,
ket and g e are played on the
baya. Dha and dhin are
compound strokes played with both hands. Thus
compositions can be sung as well as played.
The sequence of bols in a composition is constrained
aesthetically by a variety of implicit rules and conventions.
The sequence of bols in a phrase of tabla reflects a stylistic
tradition; a given sequence may be common or rare (and
stylistically incorrect). Further constraints on the bols
reflect the tala, the metric framework of the
composition.
VISUAL AND AUDIO INTERACTION
The user sees a pair of drums for input, a video display
monitor, and audio speakers. The display presents both
circular and linear timelines of the interaction. The meter is
marked with an animated beat marker and an audible
metronome click. (See Figure 1.) In time with the beat, the
user taps out a rhythmic pattern on the two drums. The
system echoes the rhythm as an unembellished rhythmic
phrase, and marks the drum beats on the rhythmic cycle
display. Then, using the tabla phrase recognizer, the system
transforms the rhythm into a grammatically correct tabla
pattern. This pattern is then displayed, played back to the
user as drum sounds, and sung back as verbal bols.
Throughout the duration of this interaction, the display
offers a persistent visual record of the interaction, and
graphically shows the correspondence between the user's
input rhythm and the system's output.
FIGURE 1 shows an sample interaction. The user taps out
the sequence: B-BLR-R---L-R ( i.e., both hands, pause,
both, left, right,...: the rhythm is the same as "Shave and a
haircut - two bits".) The system's response would be
dha - dha ge tun - na - - - ket - ta -.
The current beat is marked by the solid ball on the top row
and on the circle. The user's input is marked on the second
row, with left hand hits marked by the large circle, and right
hand hits marked by the small circle. The system output is
displayed on the next row. The shading indicates timbre,
and the bols are displayed as text below. For example,
dha is a compound stroke composed of
ge and na. The current beat is
highlighted in each line by a dark outline. Playback repeats
cyclically until the user taps a new phrase. By varying the
input rhythm, the user can explore variations of tabla
phrasing.
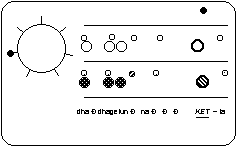 FIGURE 1.
FIGURE 1.





